| JavaScript | |||
|---|---|---|---|---|
| Prev | Home | Up | Next |
| Availability: |
| ||||||||
| Property/method value type: | Number primitive | ||||||||
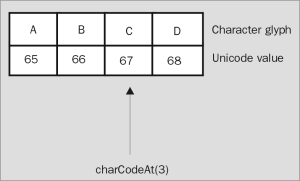
| JavaScript syntax: | - | myString.charCodeAt(aPosition) | |||||||
| Argument list: | aPosition | A valid character position within the string. | |||||||
This method returns the Unicode code point of the character at the indicated position.
Note that the string index positions start at 0 and not 1.
If there is no character at the indicated position the NaN value will be returned.
This method may involve the receiver being converted to a string and so it can be applied generically to many kinds of objects.
If the result of calling this method creates a null string, then you may need to put in a special case handler. At the point where the null character appears, any string value will be truncated.
For example this:
"AAA" + String.fromCharCode(0) + "BBB";
will only display the "AAA" portion of the string.
You can create other undesirable character values as well such as the delete character at the code point 127.
Characters at the code points 128 to 159 may display as question marks because they cannot be resolved to meaningful characters.
Character codes 208, 222, 240 and 254 render as a caret delimited character entity description word rather than as a single character glyph. This suggests that you should not rely on the output string having the same number of characters as the input numeric array. It also suggests there may be some problems converting number arrays to binary BLOb objects using this technique.
Note that the character code mapping does not necessarily correspond to the underlying code map of the platform the browser is running in.
<HTML>
<HEAD>
</HEAD>
<BODY>
<TABLE BORDER=1>
<TR>
<TH>Index</TH>
<TH>Char</TH>
<TH>Code</TH>
</TR>
<SCRIPT>
myString = "ABCDEFGHIJKLMNOPQRSTUVWXYZ";
for(myEnum=0; myEnum<myString.length; myEnum++)
{
document.write("<TR>");
document.write("<TD>");
document.write(myEnum);
document.write("</TD>");
document.write("<TD>");
document.write(myString.charAt(myEnum));
document.write("</TD>");
document.write("<TD>");
document.write(myString.charCodeAt(myEnum));
document.write("</TD>");
document.write("</TR>");
}
</SCRIPT>
</TABLE>
</BODY>
</HTML>| Prev | Home | Next |
| String.charAt() | Up | String.Class |
JavaScript Programmer's Reference, Cliff Wootton Wrox Press (www.wrox.com) Join the Wrox JavaScript forum at p2p.wrox.com Please report problems to support@wrox.com © 2001 Wrox Press. All Rights Reserved. Terms and conditions. | ||